

Công nghệ đóng gói chip 3D của TSMC và “kỳ quan bán dẫn” AMD Instinct MI300 (phần 1)
Đăng lúc
23:46 02.02.2025
Khi mặt đất không còn đủ chỗ để xây nhà thì "lên cao" là tất yếu. Nhưng trong thế giới siêu vi, đây là vấn đề không đơn giản.
Đâu là con chip phức tạp nhất từng được chế tạo? Well, trước hết cần xác định bạn muốn nói tới giai đoạn lịch sử nào vì mỗi thời sẽ có những đặc trưng riêng và do đó, câu trả lời sẽ thay đổi. Khi thế giới tạm biệt năm Giáp Thìn này và chuyển sang Ất Tỵ, cá nhân mình có 2 lựa chọn. Đó là Ponte Vecchio của Intel và MI300 của AMD. Riêng Intel, đáng ra sẽ là Rialto Bridge nhưng các drama của công ty này đã khai tử nó từ trong trứng nên chỉ còn Ponte Vecchio đang tồn tại trên thị trường là đáp ứng được.
Lại nhắc Ponte Vecchio, đáng ra con chip này sẽ nhận được nhiều điểm tín nhiệm hơn khi Intel bắt đầu đề cập tới nó sau khi Raja Koduri "chạy" từ AMD qua Intel. Nhưng con chip này phức tạp tới mức tới tận 2021 nó mới "chào sân" lần đầu và phải tận 2023 mới được tung ra thị trường. Trong khi đó AMD dù chậm chân hơn khi tới tận 2022 mới nhắc tới MI300, nhưng sang 2023 công ty này đã có thể chào hàng sản phẩm trên. Và để so sánh thì Ponte Vecchio có 100 tỷ transistor còn MI300A (bản đầu tiên) có tới 146 tỷ!

Cho tới hiện tại, Ponte Vecchio là con chip phức tạp nhất Intel từng sản xuất
Tất nhiên con số transistor không phải yếu tố quyết định xem sản phẩm nào phức tạp hơn. Trên quan điểm cá nhân mình còn đánh giá các tiêu chí về dây chuyền bán dẫn, công nghệ đóng gói chip và khả năng sản xuất hàng loạt. Dĩ nhiên bạn có thể bổ sung thêm GB200 Grace Blackwell của NVIDIA vào trong danh sách, với tổng 208 tỷ transistor. Song mình không đánh giá nó cao bằng Ponte Vecchio lẫn MI300, vì GB200 là sự kết hợp của 2 die GB100 (104 tỷ/die). Và NVIDIA có truyền thống làm die monolithic lớn nhất có thể (858 mm2 với EUV 0.33 NA) nên đây là cách "không bền vững" về lâu dài. Sang High-NA 0.55 EUV, kích thước recticle tối đa chỉ còn 1/2 nên con đường NVIDIA đang đi đã gần tới hạn.
Dĩ nhiên đây là đánh giá chủ quan của mình, bạn có thể không đồng ý với điều đó. Nhưng chốt lại sau khi điểm danh 3 cái tên thì mình chọn MI300 là đại diện phức tạp nhất từng được chế tạo cho tới hết 2024 (sang 2025 AMD có thể sẽ ra MI400 với độ phức tạp cao hơn, nên là...)

Nhưng xét tất cả các yếu tố, AMD Instinct MI300 xứng đáng đứng đầu danh sách "kỳ quan bán dẫn"
Nhưng trước hết, hãy nói một chút lý do tại sao mình viết bài này (vâng, năm nào chả có chip mới ra đời, mà con sau thì thường nhiều transistor hơn con trước). Nguyên nhân chủ yếu nằm ở định luật Moore đã tới hồi kết thúc. Sẽ có người lý luận thế lọ thế chai nhưng mình dựa trên phát biểu gốc của Gordon Moore vào 1965 rằng "số lượng transistor trên mỗi mạch điện tử tích hợp (IC) sẽ gấp đôi trong vòng 2 năm".

Nếu mang SoC hiện tại về 1965, nó không thể nào nhét vừa 1 con chip được
Bạn có thể "cãi" mạch IC có nghĩa là 1 con chip, không bắt buộc con chip đó phải là 1 die (monolithic) duy nhất. Song ở 1965 thì lúc đấy kể cả CPU cache còn chưa tồn tại, x86 chưa có mặt trên đời và tất cả mọi lý thuyết SoC đều như "vịt nghe sấm" với giới công nghệ lúc bấy giờ. Thực tế nếu vác con chip SoC gắn trên smartphone hôm nay về 1965 và hô biến nó ra trình độ bán dẫn lúc bấy giờ thì nó to hơn cả cái máy tính trạm. Và bạn có gọi cả cái máy trạm là một mạch IC không? Mình thì không.
Tất nhiên vào 1965, thế giới cũng chưa có khái niệm về thiết kế MCM (multi-die module) hay chiplet. Nên không thể bảo logic của Moore bao hàm cả chiplet. Nhìn chung, một mạch IC với mình là một die chip duy nhất. Và thiết kế monolithic đang dần tới hồi kết như đã nêu ở trên. Để đạt hệ số NA cao (giúp vẽ mạch bán dẫn chi tiết hơn) thì giới hạn recticle/photomask càng nhỏ lại. Mà diện tích die hẹp lại thì số transistor có thể "nhồi nhét" vào dĩ nhiên là cũng giảm. Tính tới hiện tại, một die monolithic dựa trên node TSMC N3 có thể đạt tối đa khoảng 170 tỷ transistor (197 triệu/mm2 * 858 mm2), nhưng đó là trên lý thuyết, thực tế thấp hơn rất nhiều (vì còn phải chia phần cho SRAM). Nên có thể nói cứ đi "con đường" monolithic thì sớm muộn bạn cũng "đâm đầu vô tường".
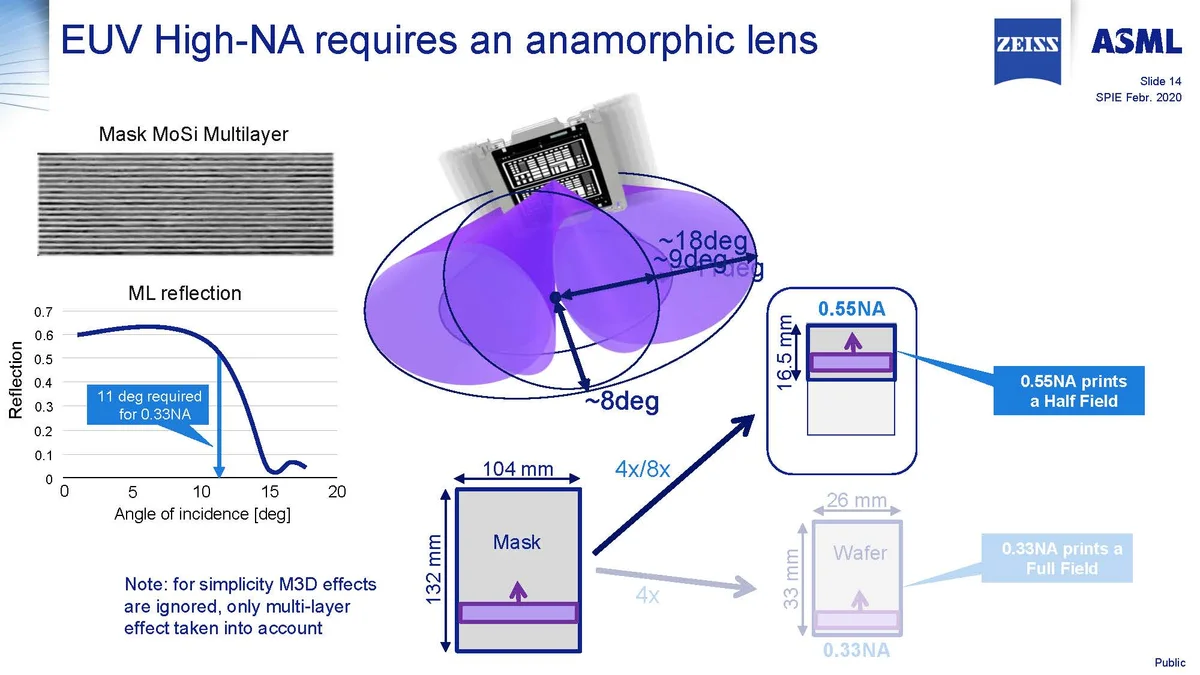
Do giới hạn quang học, High-NA EUV sẽ có diện tích die tối đa chỉ bằng 1/2 0.33 NA EUV
Nên vấn đề rõ mười mươi là bạn không thể làm monolithic mãi được (tạm bỏ qua các ứng dụng không cần "đua bơi" transistor như hạ tầng mạng, điện tử gia dụng, chip quân sự…). MCM hoặc chiplet là lối thoát duy nhất cho các hãng chip hiệu năng cao.
À vâng, chiplet, thứ này đã tồn tại cả chục năm qua rồi. Có gì mới ở đây? Bạn đang thắc mắc.
Cái mới ở đây chính là khác biệt trong cách sản xuất một con chip Ryzen/EPYC vs. MI300. Nếu chỉ áp dụng những kỹ thuật làm ra con Ryzen đầu tiên thì AMD/TSMC không thể nào chế tạo được MI300. Để có thể làm ra được MI300, TSMC phải vận dụng gần như mọi "skill" mà công ty này có được tính tới hiện tại. Nói hơi quá thì đây là "quest" khó nhất mà AMD từng đề ra cho công ty Đài Loan. Thậm chí có thể nói cả Samsung Foundry lẫn Intel Foundry cũng không làm được tính tới thời điểm này. Đây cũng là lý do tại sao mình chọn MI300 thay vì Ponte Vecchio hay GB200 - mình không nói rằng 2 con chip sau không phức tạp, nhưng độ phức tạp của MI300 còn nhiều hơn thế.
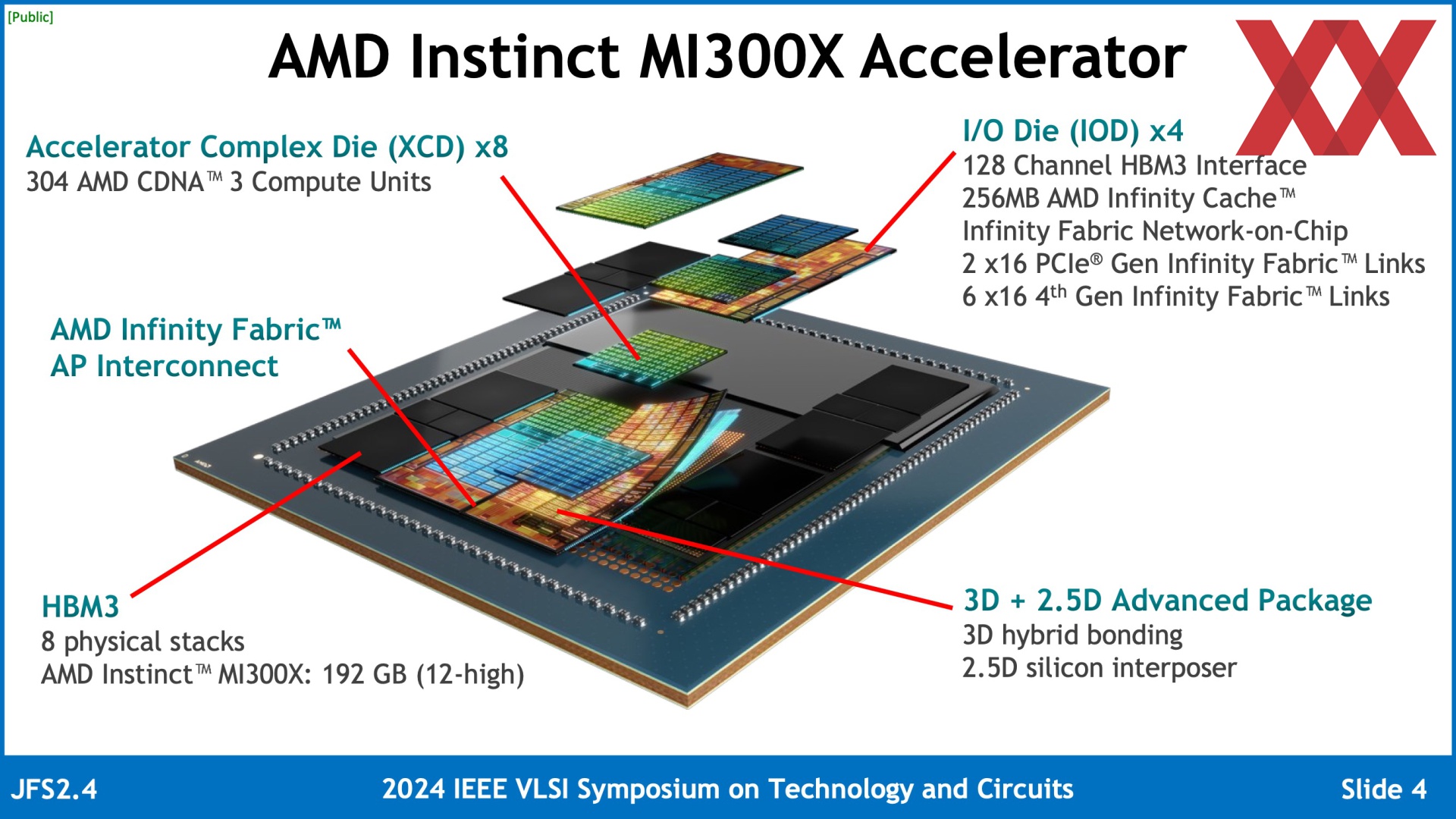
AMD dùng tất cả mọi công nghệ TSMC đang có để làm ra MI300
Có thể nói giới bán dẫn hiện nay đang chia ra 2 "đẳng cấp". Một là những hãng gia công chip theo kiểu monolithic "truyền thống" bao lâu nay. Và phần còn lại là thiểu số những công ty làm được chiplet (hoặc cao hơn là chip 3D). Tính tới hiện tại chỉ có 3 cái tên trong đám "thiểu số" gồm Intel, Samsung và TSMC. Tương lai sẽ có thêm vài cái tên khác nhưng hôm nay, chúng ta chỉ tập trung vào TSMC.

Các công nghệ đóng gói chip 3D của TSMC
3 cụm từ phía trên là 3 công nghệ đóng gói 3D mà TSMC hiện đang cung cấp cho khách hàng. 3DFabric là tên gọi chung cho tất cả các công nghệ này. Nhưng tại sao lại cần tới 3 công nghệ khác nhau chỉ để làm chip 3D? Đó là vì xây 1 căn nhà 1 tấm thì bạn không cần phân biệt trên dưới trước sau. Nhưng khi cần tới 2 căn thì tương quan vị trí và kết nối chúng sẽ thế nào?
3DFabric chia ra 2 dạng: tạo 3D trước (front-end) hay tạo 3D sau (back-end) khi cắt/test wafer. Nếu việc chồng chip diễn ra trước khi cắt wafer (FE3D), TSMC có SoIC. Còn chồng chip sau khi wafer đã cắt (BE3D), TSMC có InFO và CoWoS. Bạn có cảm giác đã thấy những cái tên này ở đâu không? SoIC được AMD dùng để sản xuất X3D (3D V-Cache), InFO dùng trên các chip Apple iPhone và CoWoS, well, hầu như mọi con chip tăng tốc AI đều dùng công nghệ này.

Cốt lõi của SoIC là kỹ thuật tạo liên kết hybrid bonding với các mạch chỉ cách nhau 9 μm (0.9 μm là sai số cho phép)
SoIC (System of Integrated Chips) hay chồng chip dọc được thực hiện chủ yếu dựa trên hybrid bonding. Cụ thể các mạch liên kết giữa 2 die chip được tạo ra bởi TSV (through-via-silicon). Khác biệt ở đây là cự ly hybrid bonding cực kỳ nhỏ, từ 9 μm (thế hệ 1) trở xuống. Theo lộ trình của TSMC, hybrid bonding thế hệ 2 bắt đầu triển khai trong 2024 có cự ly chỉ còn 6 μm. Thế hệ 3 còn 4.5 μm và thế hệ 4 là 3 μm. Trong bài phân tích X3D trước, mình có mô tả cách TSMC thực hiện như thế nào, bạn có thể xem lại.
SoIC lại chia ra 2 dạng là CoW (chip on wafer) và WoW (wafer on wafer). CoW là khi 2 die chip có kích thước khác nhau (ví dụ X3D thế hệ đầu), con chip nhỏ hơn sẽ được đặt nằm trên wafer chứa die chip lớn hơn rồi hybrid bonding mới được thực hiện. WoW là khi 2 die chip có kích thước bằng nhau (có thể X3D đời sau đang dùng dạng này), về nguyên tắc chúng có thể được cắt nhỏ ra cùng lúc. Lúc này TSMC sẽ chồng 2 wafer lên nhau (sao cho các vị trí TSV khít nhất có thể) rồi tiến hành hybrid bonding. Sau đó mới diễn ra công đoạn cắt, test thành phẩm.
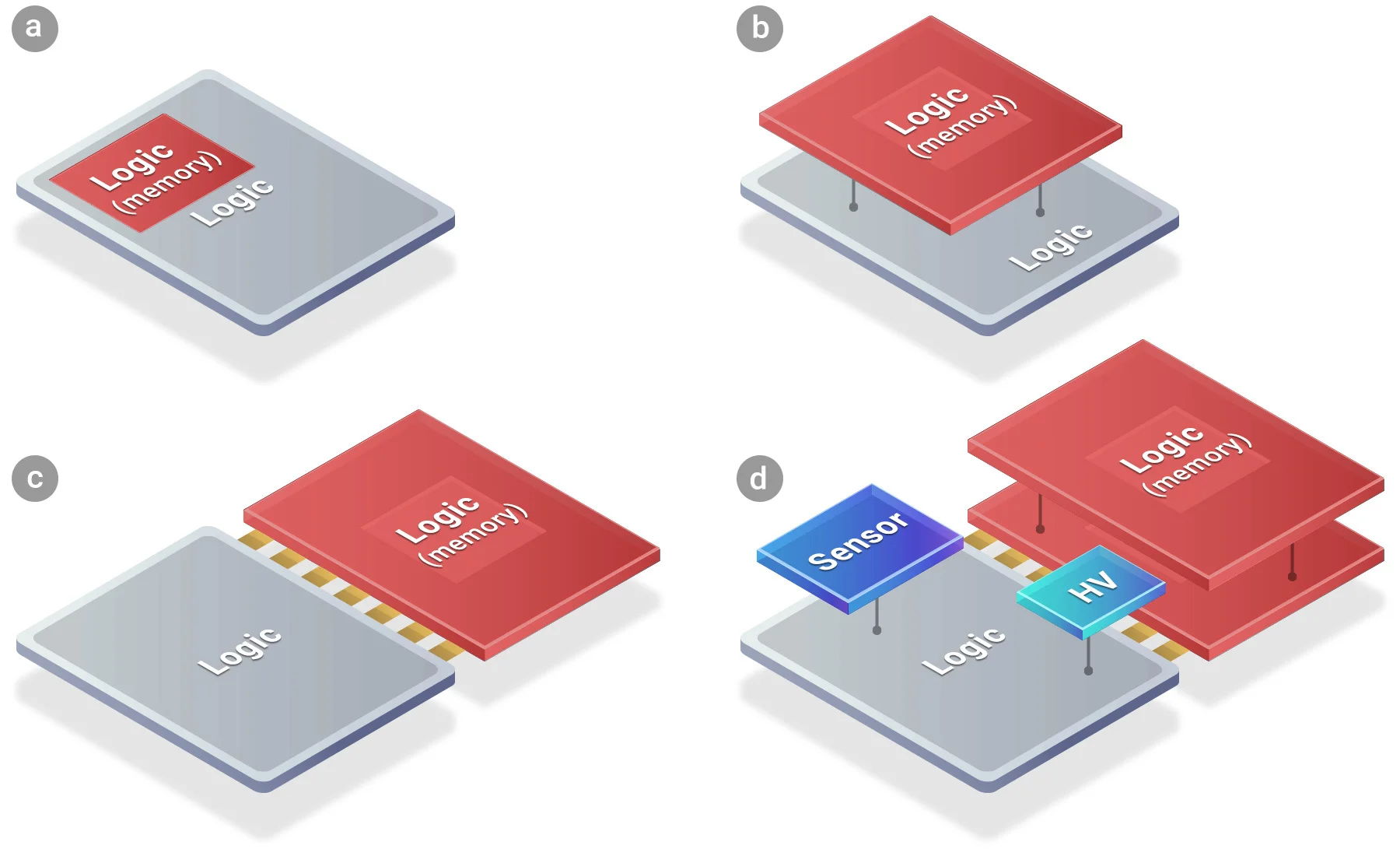
Ở CoW, die chip nhỏ hơn được cắt ra trước rồi mới "hàn" lên die chip lớn hơn
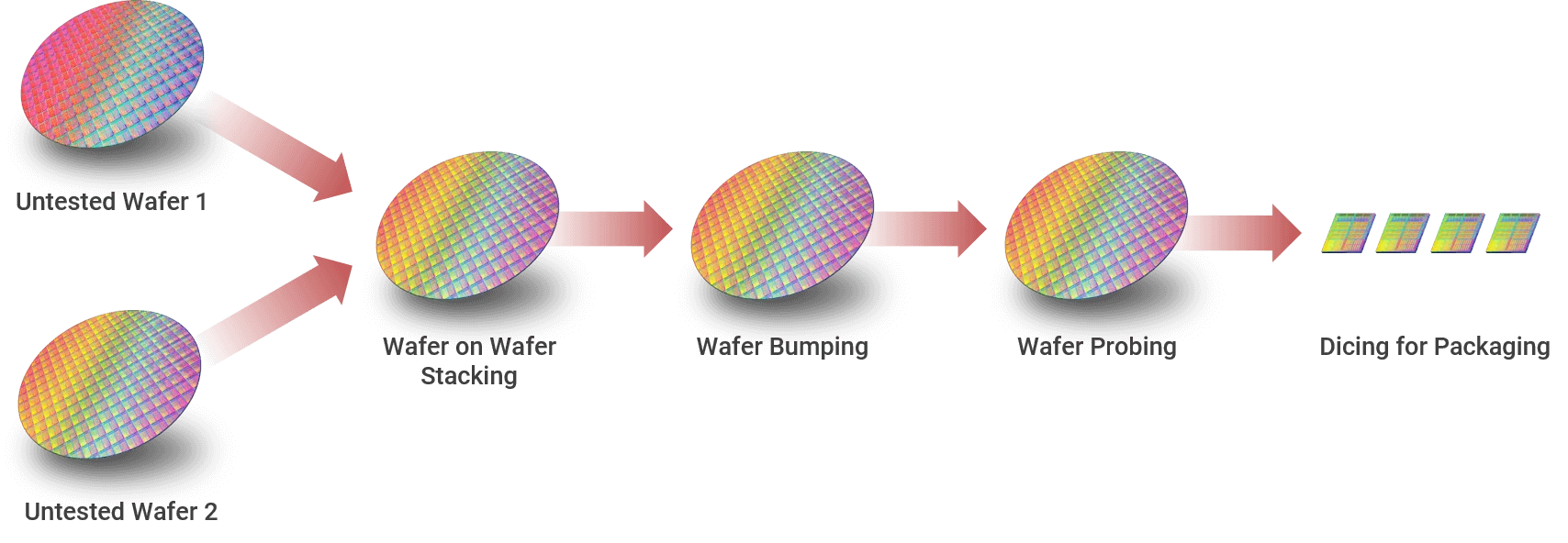
Ở WoW, 2 wafer được chồng lên nhau trước, "hàn" lại rồi mới cắt ra sau

Đâu là con chip phức tạp nhất từng được chế tạo? Well, trước hết cần xác định bạn muốn nói tới giai đoạn lịch sử nào vì mỗi thời sẽ có những đặc trưng riêng và do đó, câu trả lời sẽ thay đổi. Khi thế giới tạm biệt năm Giáp Thìn này và chuyển sang Ất Tỵ, cá nhân mình có 2 lựa chọn. Đó là Ponte Vecchio của Intel và MI300 của AMD. Riêng Intel, đáng ra sẽ là Rialto Bridge nhưng các drama của công ty này đã khai tử nó từ trong trứng nên chỉ còn Ponte Vecchio đang tồn tại trên thị trường là đáp ứng được.
Những cái tên nổi bật
Lại nhắc Ponte Vecchio, đáng ra con chip này sẽ nhận được nhiều điểm tín nhiệm hơn khi Intel bắt đầu đề cập tới nó sau khi Raja Koduri "chạy" từ AMD qua Intel. Nhưng con chip này phức tạp tới mức tới tận 2021 nó mới "chào sân" lần đầu và phải tận 2023 mới được tung ra thị trường. Trong khi đó AMD dù chậm chân hơn khi tới tận 2022 mới nhắc tới MI300, nhưng sang 2023 công ty này đã có thể chào hàng sản phẩm trên. Và để so sánh thì Ponte Vecchio có 100 tỷ transistor còn MI300A (bản đầu tiên) có tới 146 tỷ!
Cho tới hiện tại, Ponte Vecchio là con chip phức tạp nhất Intel từng sản xuất
Tất nhiên con số transistor không phải yếu tố quyết định xem sản phẩm nào phức tạp hơn. Trên quan điểm cá nhân mình còn đánh giá các tiêu chí về dây chuyền bán dẫn, công nghệ đóng gói chip và khả năng sản xuất hàng loạt. Dĩ nhiên bạn có thể bổ sung thêm GB200 Grace Blackwell của NVIDIA vào trong danh sách, với tổng 208 tỷ transistor. Song mình không đánh giá nó cao bằng Ponte Vecchio lẫn MI300, vì GB200 là sự kết hợp của 2 die GB100 (104 tỷ/die). Và NVIDIA có truyền thống làm die monolithic lớn nhất có thể (858 mm2 với EUV 0.33 NA) nên đây là cách "không bền vững" về lâu dài. Sang High-NA 0.55 EUV, kích thước recticle tối đa chỉ còn 1/2 nên con đường NVIDIA đang đi đã gần tới hạn.
Dĩ nhiên đây là đánh giá chủ quan của mình, bạn có thể không đồng ý với điều đó. Nhưng chốt lại sau khi điểm danh 3 cái tên thì mình chọn MI300 là đại diện phức tạp nhất từng được chế tạo cho tới hết 2024 (sang 2025 AMD có thể sẽ ra MI400 với độ phức tạp cao hơn, nên là...)
Nhưng xét tất cả các yếu tố, AMD Instinct MI300 xứng đáng đứng đầu danh sách "kỳ quan bán dẫn"
Moore's Law Is Dead
Nhưng trước hết, hãy nói một chút lý do tại sao mình viết bài này (vâng, năm nào chả có chip mới ra đời, mà con sau thì thường nhiều transistor hơn con trước). Nguyên nhân chủ yếu nằm ở định luật Moore đã tới hồi kết thúc. Sẽ có người lý luận thế lọ thế chai nhưng mình dựa trên phát biểu gốc của Gordon Moore vào 1965 rằng "số lượng transistor trên mỗi mạch điện tử tích hợp (IC) sẽ gấp đôi trong vòng 2 năm".
Nếu mang SoC hiện tại về 1965, nó không thể nào nhét vừa 1 con chip được
Bạn có thể "cãi" mạch IC có nghĩa là 1 con chip, không bắt buộc con chip đó phải là 1 die (monolithic) duy nhất. Song ở 1965 thì lúc đấy kể cả CPU cache còn chưa tồn tại, x86 chưa có mặt trên đời và tất cả mọi lý thuyết SoC đều như "vịt nghe sấm" với giới công nghệ lúc bấy giờ. Thực tế nếu vác con chip SoC gắn trên smartphone hôm nay về 1965 và hô biến nó ra trình độ bán dẫn lúc bấy giờ thì nó to hơn cả cái máy tính trạm. Và bạn có gọi cả cái máy trạm là một mạch IC không? Mình thì không.
Tất nhiên vào 1965, thế giới cũng chưa có khái niệm về thiết kế MCM (multi-die module) hay chiplet. Nên không thể bảo logic của Moore bao hàm cả chiplet. Nhìn chung, một mạch IC với mình là một die chip duy nhất. Và thiết kế monolithic đang dần tới hồi kết như đã nêu ở trên. Để đạt hệ số NA cao (giúp vẽ mạch bán dẫn chi tiết hơn) thì giới hạn recticle/photomask càng nhỏ lại. Mà diện tích die hẹp lại thì số transistor có thể "nhồi nhét" vào dĩ nhiên là cũng giảm. Tính tới hiện tại, một die monolithic dựa trên node TSMC N3 có thể đạt tối đa khoảng 170 tỷ transistor (197 triệu/mm2 * 858 mm2), nhưng đó là trên lý thuyết, thực tế thấp hơn rất nhiều (vì còn phải chia phần cho SRAM). Nên có thể nói cứ đi "con đường" monolithic thì sớm muộn bạn cũng "đâm đầu vô tường".
Do giới hạn quang học, High-NA EUV sẽ có diện tích die tối đa chỉ bằng 1/2 0.33 NA EUV
Nên vấn đề rõ mười mươi là bạn không thể làm monolithic mãi được (tạm bỏ qua các ứng dụng không cần "đua bơi" transistor như hạ tầng mạng, điện tử gia dụng, chip quân sự…). MCM hoặc chiplet là lối thoát duy nhất cho các hãng chip hiệu năng cao.
À vâng, chiplet, thứ này đã tồn tại cả chục năm qua rồi. Có gì mới ở đây? Bạn đang thắc mắc.
Cái mới ở đây chính là khác biệt trong cách sản xuất một con chip Ryzen/EPYC vs. MI300. Nếu chỉ áp dụng những kỹ thuật làm ra con Ryzen đầu tiên thì AMD/TSMC không thể nào chế tạo được MI300. Để có thể làm ra được MI300, TSMC phải vận dụng gần như mọi "skill" mà công ty này có được tính tới hiện tại. Nói hơi quá thì đây là "quest" khó nhất mà AMD từng đề ra cho công ty Đài Loan. Thậm chí có thể nói cả Samsung Foundry lẫn Intel Foundry cũng không làm được tính tới thời điểm này. Đây cũng là lý do tại sao mình chọn MI300 thay vì Ponte Vecchio hay GB200 - mình không nói rằng 2 con chip sau không phức tạp, nhưng độ phức tạp của MI300 còn nhiều hơn thế.
AMD dùng tất cả mọi công nghệ TSMC đang có để làm ra MI300
TSMC 3DFabric - SoIC, InFO và CoWoS
Có thể nói giới bán dẫn hiện nay đang chia ra 2 "đẳng cấp". Một là những hãng gia công chip theo kiểu monolithic "truyền thống" bao lâu nay. Và phần còn lại là thiểu số những công ty làm được chiplet (hoặc cao hơn là chip 3D). Tính tới hiện tại chỉ có 3 cái tên trong đám "thiểu số" gồm Intel, Samsung và TSMC. Tương lai sẽ có thêm vài cái tên khác nhưng hôm nay, chúng ta chỉ tập trung vào TSMC.
Các công nghệ đóng gói chip 3D của TSMC
3 cụm từ phía trên là 3 công nghệ đóng gói 3D mà TSMC hiện đang cung cấp cho khách hàng. 3DFabric là tên gọi chung cho tất cả các công nghệ này. Nhưng tại sao lại cần tới 3 công nghệ khác nhau chỉ để làm chip 3D? Đó là vì xây 1 căn nhà 1 tấm thì bạn không cần phân biệt trên dưới trước sau. Nhưng khi cần tới 2 căn thì tương quan vị trí và kết nối chúng sẽ thế nào?
3DFabric chia ra 2 dạng: tạo 3D trước (front-end) hay tạo 3D sau (back-end) khi cắt/test wafer. Nếu việc chồng chip diễn ra trước khi cắt wafer (FE3D), TSMC có SoIC. Còn chồng chip sau khi wafer đã cắt (BE3D), TSMC có InFO và CoWoS. Bạn có cảm giác đã thấy những cái tên này ở đâu không? SoIC được AMD dùng để sản xuất X3D (3D V-Cache), InFO dùng trên các chip Apple iPhone và CoWoS, well, hầu như mọi con chip tăng tốc AI đều dùng công nghệ này.
Cốt lõi của SoIC là kỹ thuật tạo liên kết hybrid bonding với các mạch chỉ cách nhau 9 μm (0.9 μm là sai số cho phép)
SoIC (System of Integrated Chips) hay chồng chip dọc được thực hiện chủ yếu dựa trên hybrid bonding. Cụ thể các mạch liên kết giữa 2 die chip được tạo ra bởi TSV (through-via-silicon). Khác biệt ở đây là cự ly hybrid bonding cực kỳ nhỏ, từ 9 μm (thế hệ 1) trở xuống. Theo lộ trình của TSMC, hybrid bonding thế hệ 2 bắt đầu triển khai trong 2024 có cự ly chỉ còn 6 μm. Thế hệ 3 còn 4.5 μm và thế hệ 4 là 3 μm. Trong bài phân tích X3D trước, mình có mô tả cách TSMC thực hiện như thế nào, bạn có thể xem lại.
SoIC lại chia ra 2 dạng là CoW (chip on wafer) và WoW (wafer on wafer). CoW là khi 2 die chip có kích thước khác nhau (ví dụ X3D thế hệ đầu), con chip nhỏ hơn sẽ được đặt nằm trên wafer chứa die chip lớn hơn rồi hybrid bonding mới được thực hiện. WoW là khi 2 die chip có kích thước bằng nhau (có thể X3D đời sau đang dùng dạng này), về nguyên tắc chúng có thể được cắt nhỏ ra cùng lúc. Lúc này TSMC sẽ chồng 2 wafer lên nhau (sao cho các vị trí TSV khít nhất có thể) rồi tiến hành hybrid bonding. Sau đó mới diễn ra công đoạn cắt, test thành phẩm.
Ở CoW, die chip nhỏ hơn được cắt ra trước rồi mới "hàn" lên die chip lớn hơn
Ở WoW, 2 wafer được chồng lên nhau trước, "hàn" lại rồi mới cắt ra sau
==***==
Khoá học: Quản trị Chiến lược Dành cho các Lãnh đạo Doanh nghiệp

Nhấn vào đây để bắt đầu khóa học
Khóa học: Trở thành chuyên gia Bảo mật và tấn công ANM- Hacker mũ trắng

Nhấn vào đây để bắt đầu khóa học
Chuyên gia phân tích, tự động hóa Web iMacros

Nhấn vào đây để bắt đầu khóa học
Xây dựng ứng dụng tự động hóa AutoIT

Nhấn vào đây để bắt đầu khóa học
Khóa đào tạo Hacker và Marketing Facebook từ A - Z

Nhấn vào đây để bắt đầu khóa học
Khóa học: Phân tích và trực quan hóa dữ liệu với Power BI

Nhấn vào đây để bắt đầu khóa học
Khóa học đào tạo Marketing Facebook thông minh
![]()
Nhấn vào đây để bắt đầu khóa học
Lập trình Visual Foxpro 9 - Dành cho nhà quản lý và kế toán

Nhấn vào đây để bắt đầu khóa học
Làm chủ xây dựng Game chuyên nghiệp

Nhấn vào đây để bắt đầu khóa học
Trở thành chuyên gia Marketing Facebook thông minh
![]()
Nhấn vào đây để bắt đầu khóa học
Kỹ sảo Điện ảnh đỉnh cao với khóa học After Effect

Nhấn vào đây để bắt đầu khóa học
Trở thành chuyên gia Vẽ Đẳng Cấp với khóa học AI

Nhấn vào đây để bắt đầu khóa học
Làm Chủ thiết kế ảnh với Photoshop CC

Nhấn vào đây để bắt đầu khóa học
Dựng Phim Siêu đẳng với Adobe Premiere

Nhấn vào đây để bắt đầu khóa học
Khóa dựng phần mềm quản lý dành cho nhà Quản lý và Kế toán bằng MS ACCESS

Nhấn vào đây để bắt đầu khóa học
Khóa học Machine Learning cơ bản-Khoa học dữ liệu - AI

Nhấn vào đây để bắt đầu khóa học
Khóa học Đào tạo sử dụng Excel Chuyên nghiệp & ứng dụng

Nhấn vào đây để bắt đầu khóa học
Khóa học sử dụng PowerPoint Chuyên nghiệp & ứng dụng

Nhấn vào đây để bắt đầu khóa học
Khóa học xây dựng và quản trị hệ thống đào tạo trực tuyến

Nhấn vào đây để bắt đầu khóa học





ĐĂNG KÝ/LIÊN HỆ:
- Tòa nhà The GoldenPalm, 21 Lê Văn Lương, Phường Nhân Chính, Thanh Xuân, Hà Nội.
- 098 909 5293
- hotrotudaotao@gmail.com
- DINH FAMILY lIBRARY
- YouTube
